
More Data on Writing about Data: Details on the 5 Cases Evaluated for Readability
Detailed data on the 5 cases used for my evaluations of 7 readability tools. Supplement to "Write on! 7 free tools for more readable writing on a shoestring".

This post is for “scuba divers” who like to go really deep on data. It shares ocean-floor-level details and data on the 5 example cases I used for my evaluation of readability analysis tools.
Next up: my decision on which tool(s) to use in my ‘ethical shoestring’ toolkit.
Post Contents:
Acronyms
GL = Grade Level
Readability Analysis tool names
CC = Character Calculator
DY = Datayze
GRAM = Grammarly
RF = Readability Formulas
TCR = TextCompare Readabilit (not a typo; it’s how they spell the product name)
WC = WordCalc
WFX = WebFX Read-Able
WORD = Microsoft Word
Readability metric names
ARI = Automated Readability Index GL
FRE = Flesch Reading Ease score
FKGL = Flesch-Kincaid GL
FOG = Gunning Fog Index GL
FOR = FORCAST GL
LW= Linsear Write GL
SMOG = Simple Measure of Gobbledygook Index GL
Details on Case 1: LinkedIn post about my Datawrapper article
This was a short post (64 words) pointing people to Substack. I manually counted 3 sentences. If its compound sentence is treated as 2, it would be 4 sentences total.
On rich text input, Datayze somehow counted 10 sentences instead of 3 or 4. This skewed all Datayze metrics to score the post as more readable than it was.
With the rich text input, TextCompare was the most negative across the tools, by 5+ grade levels. WordCalc was more positive than most other tools. CharacterCalculator, ReadabilityFormulas, and WebFX Read-able were in the middle. There were extreme variations across the tools in their calculated values for the same metric, e.g. ARI. (Max from 1 tool was 3x the min from another.)
I repeated the calculations with TXT input. After re-running the tool with TXT input, Datayze counted 3 sentences.
Lesson: Use TXT input for the remainder of this evaluation.
Even with TXT, results for Case 1 varied across tools for every metric. LW and FRE were the most consistent metrics across all 6 tools (lowest normalized standard deviation). SMOG index was the most inconsistent; the optimistic WordCalc even scored SMOG as high.

On investigating, I found that not all of the base data counts match across tools, either. Sentence and word counts were close; character and syllable counts varied.

Details on Case 2: “Measuring writing effort”.
This post was about 400 words and had footnotes. Even with the footnote texts truncated from the end, the reference numbers remained in the body of the post. My first tests showed that some tools fail to recognize a period as the end of a sentence if a footnote number is right after the period! (Example: “last word.12 New sentence …”) Some of the tools counted 2 sentences as 1, reducing sentence count and increasing average words per sentence. Both effects worsen readability scores.
Inserting a space between the period and the footnote number helped.
Moving the footnote number before the period also helped.
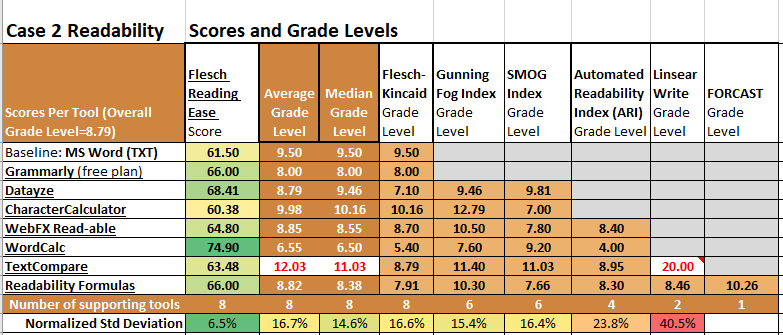
For some reason, TextCompare calculated grade level=20 for LW. This is way out of whack with the rest of the grade levels on this post (max=12.79). The counts show no obvious reason for the anomaly, but they are incomplete. TextCompare doesn’t share the complex word counts it uses in calculating LW.

Details on Case 3: LinkedIn post on ageism.
On the scores and grade levels, WordCalc was again the most positive. TextCompare was somewhat negative, but not as much as in Case 1, and it was similar to Character Calculator. For some reason, TextCompare was very low on its LW value this time - almost as low as WordCalc on FKGL (7.7 and 7.3, vs. the overall average of 10.4).

Character, word, syllable, and paragraph counts were fairly consistent on this post. Most tools counted 22 sentences with TXT input. Datayze showed 27 sentences. RF counted 27 lines and 22 sentences and used 27 in the formulas.

Details on Case 4: “More Than Melodies”.
The post title “[Bonus]” inside the original Case 4 DOCX file confused ReadabilityFormulas. It alerted that it found non-text characters in the first 20 and would not process the post at all.

I removed the [] and then it worked. This is an odd little bug, which I’ll probably report so it can be fixed, but it’s minor.
Lesson: Until RF fixes this, avoid [] in posts or strip them before scoring.
With Datayze, the initial paste from the Word “plain text” file yielded 289 sentences. After tedious manual editing to remove the line breaks it mysteriously inserted into the pasted text, the count was 122 sentences. Pasting from a TXT file instead avoided the insertion of the line breaks and yielded 123 sentences. 🤷♀️
Lesson: With Datayze, stick to pasting TXT input.
As another test, I removed all of the footnote numbers and re-scored with RF. On such a long post, the difference was “in the noise”. FRE went from 52 to 51, FKGL from 10.28 to 10.29, ARI from 10.27 to 10.66, FOR from 11.22 to 11.14, FOG from 14.0 to 13.9, LW from 11.65 to 11.45, and SMOG from 10.56 to 10.47.
Lessons: Don’t bother editing my past posts to remove footnote references before scoring. For future articles, insert footnotes before periods. Or just use hyperlinks instead of endnotes.
I experimented with TextCompare to see if I could figure out why it under-counts sentences. Removing the references section helped. But it still seemed to be confused by the footnote references in the body of the post. In the example below, footnote 22 right after the period kept the end of the sentence from being recognized. As a result, it combined 2 sentences into one 48-word sentence:

I tested a workaround of inserting a space before the footnote, or moving the footnote before the period. This solved the problem but was tedious. Oddly, TextCompare now flagged an even longer “longest sentence” at 70 words. Two numbered lists were treated as compound sentences. And since the last bullet in the first list (“purposes”) didn’t end with a period, TextCompare ignored the line breaks and treated both lists as one long sentence.

Lesson: For future, either:
end bullets with periods and avoid introducing lists with colons, or
accept that tools counting only “sentences” and not “lines” are going to be somewhat wrong on my posts, or
don’t use tools that don’t handle this well.
After switching to TXT input and removing endnotes, all of the metrics and data measures improved. These changes raised the sentence count and lowered the per-sentence averages. Sentence counts still showed high variability across the tools, though (see table below for details).
For Grade Levels, WC was again the lowest, especially on ARI. TCR and CC were again the highest, both on FOG.
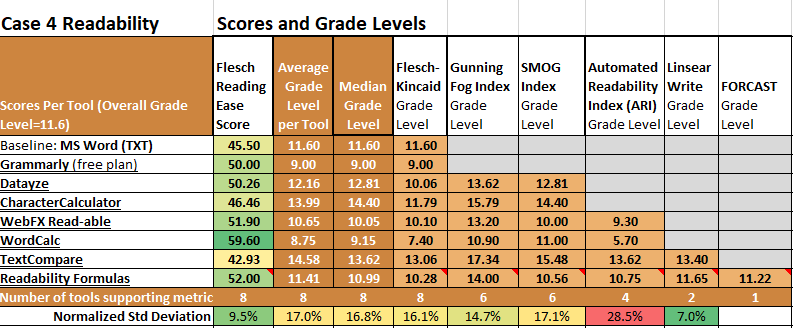
Some quirks remained. RF reported the longest word as “cloningsynthesis”. I had used a slash to separate those words (“voice cloning/synthesis”). When words are separated by punctuation without surrounding spaces, the separation between the words seems to be lost when processing strips the punctuation. As a test, I inserted spaces around the slash and re-scored. The word counts changed slightly, and the new longest word was “individualized”.
Lesson: Use one of these 3 workarounds.
Ensure I always put spaces before and after a “/” when I use it.
Stop using a “/” between words.
Accept that my counts and metrics are going to be a bit off.

Details on Case 5: “The older kids are not alright”.
At ~4600 words, this is one of the two longest posts I’ve published to date. It’s on ageism, not on AI or a technical topic. It cites some data and has 45 references.
All of the tools except RF were able to handle the full post. All calculations were completed in under 5 seconds. To be consistent, all scoring used the text that had been truncated to 3464 words, as noted above.
With the TXT input, the data variation patterns observed in the smaller posts held. Using rich text, Datayze somehow came up with a sentence count of 727, vs. an average of 231 for the 4 tools that didn’t truncate the post. That drove all Datayze metrics to low grade levels (too optimistic). This appeared to be due to the mishandling of the pasted text input, as mentioned earlier. With TXT input, Datayze came in at 238 sentences, nearly 20% higher than all others.
Note: TCR generated another wild outlier for LW (29)!
Even without the outlier, TCR is the most negative. WC is again the most positive.

RF again used its line count instead of sentences (202 vs. 160) for metrics, due to more than 20% of the lines not ending with punctuation. WebFX came in at 353 with rich text (quite high) and at 199 with TXT. Like Grammarly (at 198), and WC (at 200), it might also be quietly using lines instead of sentences.

References
TO DO: Add links to final post after it is published.
Data on Writing about Data: Results from trying 7 online readability tools

I’m on a 2024 quest to become a more readable writer. I’ve looked into readability metrics, chose 6, surveyed 14 readability analysis tools, and chose 7 to evaluate. This post shares my evaluation results. Next up: my decision on which tool(s) to use in my ‘
Worth a try? A look at 14 readability analysis tools

My main post on readability metrics, tools, and evaluations is here (coming soon!). Four bonus pages provide details: Readability features of Microsoft Word and why I’m looking for a new tool. What “readable” means, 16 metrics, the 6 I chose to evaluate, and why.
What’s “readable”? 16 readability metrics and what they miss

My main post on readability (metrics, tools, and evaluations) is here (coming soon!). Four bonus pages provide details: Readability features of Microsoft Word and why I’m looking for a new tool. What “readable” means, 16 metrics, the 6 I chose to evaluate, and why. [
Using MS Word for Readability Analysis

I’ve used Word’s size and readability statistics on 3 months of Substack and LinkedIn posts from this year. My conclusion is that the Readability Statistics in Word are too flaky to be useful, and I need to find a better tool. Here’s why. Details on Microsoft Word’s Readability Features