
Adventures in datawrapping: Charts and tables and graphs, oh my
3 experiments with embedding "vizzes" for data tables and graphs in Substack posts with Datawrapper, lessons learned, and next steps

This post is mostly for people who are curious about “vizzes”, or data visualizations. Please check out these experiments and let me know, in the 2 Polls, which viz options you think are best for each 🙂.

Table of contents for this post:
The Challenge: Efficiently embedding non-trivial tables and graphs in Substack posts
I’ve been writing on Substack for 3 months now. In general, I am enjoying the writing experience here. I do still wish I could write posts in the mobile app, but I’m adapting to that. I also wish we had more flexible formatting options.
Many of my technical posts use & share data visualizations. Including data tables or graphs seems to be one of the least efficient writing tasks. Substack has some native post design and editing options, but they aren’t meeting my needs.
The ‘financial chart’ option is specific to querying and graphing financial data.
I know how to create tables in HTML, but the Substack editor doesn’t support embedding HTML.
LaTeX doesn’t seem like an optimal option for everything I’m missing.
I found articles saying LaTeX can generate plots with PGFPlots, e.g. 1. However, if I have to invest in learning something new for my dataviz needs, I’m not convinced LaTeX is where my time should go.
To date, I’ve been creating Excel workbooks and saving tables & graphs as pictures to insert into Substack posts. PNGs don’t provide great UX, though:
Pictures of tables or graphs can be difficult to read on small screens or devices.
PNG images in posts don’t support searching, sorting, or interactively exploring or manipulating the contents.
Potential Solution: Datawrapper
Last weekend, I accidentally tripped over a Substack support article2 which indicated that Datawrapper.de might be a better way to do what I need with tables and graphs. I checked out Datawrapper this week. I found:
They have a great FREE plan3 (important for shoestring operations like mine).
They not only support graphs and charts, they support interactive tables!
They do not sell or reuse data provided by customers. They are based in Germany and are GDPR compliant.4
Their “Datawrapper Academy” provides good, clear guidance on how to do things, and even why5 (e.g. why 2-Y-axis overlay charts are not recommended)6.
I have to challenge Datawrapper’s advice that charts with two Y-axis scales should be avoided, though. Applying 2 measurement scales (e.g. Celsius and Fahrenheit) to the same data is the only 2-Y-axis example they approve. However, I’ve used a classic Pareto chart many times in my career. I even wrote HP minicomputer software to generate Paretos automatically on HP plotters and graphics devices back in the olden days. Two vertical Y-axes with different scales are mandatory!
The left Y-axis of a Pareto chart displays the count (frequency) of the number of items (0-max), shown in columns of descending heights.
The right Y-axis displays the cumulative percentage of the total (0%-100%), shown by an overlaid ascending line.
Pareto charts should also be a valid exception to the 1-Y-axis rule. 😊
This isn’t just a theoretical objection. I used several Pareto-style charts in my April retrospective. Reading their advice article got me worried that I might not be able to duplicate these charts in Datawrapper, which would be a bummer. So this chart type, more generally “combo graphs”, became Experiment 1.
Experiment 1: Combo graphs
In my monthly retrospectives, I analyze data about my writing, and I now include graphs in my posts. Here’s one of the static Excel graph images from the data analysis for my April retrospective7 . It’s a Pareto-style chart showing the distribution of my post lengths. (A true Pareto chart would have sorted the buckets into descending order by frequency. I wanted to show the cumulative post lengths, i.e. what percentage of posts were less than X words, so I kept the buckets in order by length.)
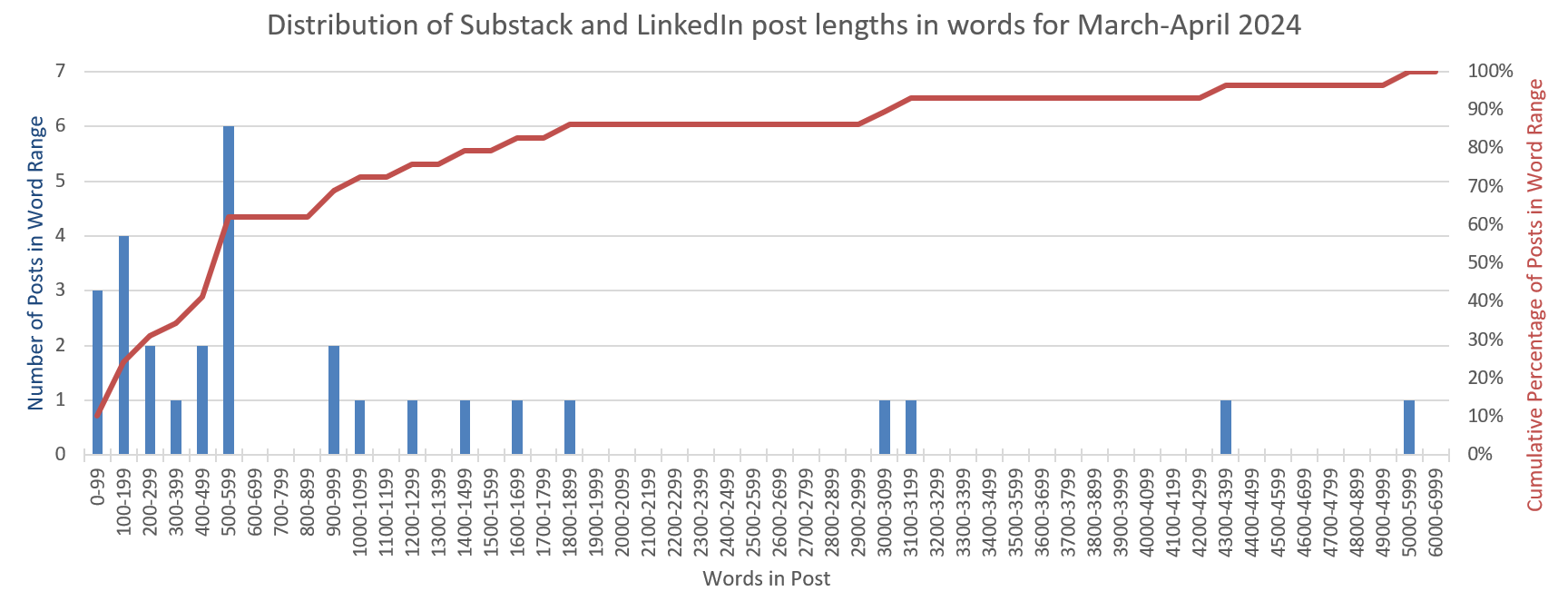
My old desktop version of Excel doesn’t do these charts out of the box. That means I had to manually create a data sheet with the 100-word “buckets” in this graph, and use formulas - to count the number of posts in each bucket, and to calculate the cumulative percentages. That was easy enough. Then I used the Excel “combo chart” style to create the diagram.
With the data already bucketed, to reproduce this chart in Datawrapper, I simply need to create a composite bar-line chart with the bucketed data.
I completely ran into a wall, though. Datawrapper doesn’t offer a combo chart that has columns for a first parameter and a line for a second parameter, either overlaid on the same axes or on separate axes. This “Multiple Line” chart is as close as I could get:
I messaged Datawrapper.de support via email and through their contact form to see if there is any way to get a Pareto-style chart with columns on the upper graph. On May 29, they politely confirmed that it is not yet possible.
I’ve asked Datawrapper to add Pareto chart support (and run chart support) to their feature backlog. Those 2 charts are among the 7 “basic tools of quality”!
However, it’s unlikely that different Y-axis scales will be supported. I did find a Datawrapper help article on creating a graph with lines and columns.8 I’ll experiment more with the combo style. In the meantime, I rate Experiment 1 as a miss.😔
Experiment 2: Non-Combo Graphs
As an action from my April retrospective9, I’m now capturing readability statistics on my posts. For my May retrospective, I started creating graphs of the new data last week. Most are overlaid line graphs, not Pareto-style combo charts. These aren’t final yet (data or style). Let’s see how they work in Datawrapper.
Choosing a Graph Candidate
Graph Candidate 1: Analyzing my readability data shows that average characters-per-word (according to how Word calculates it) has been fairly consistent across a wide range of post lengths and over time. These are simple graphs that should be trivial to reproduce in Datawrapper, though. I want a better candidate that will give more insight.

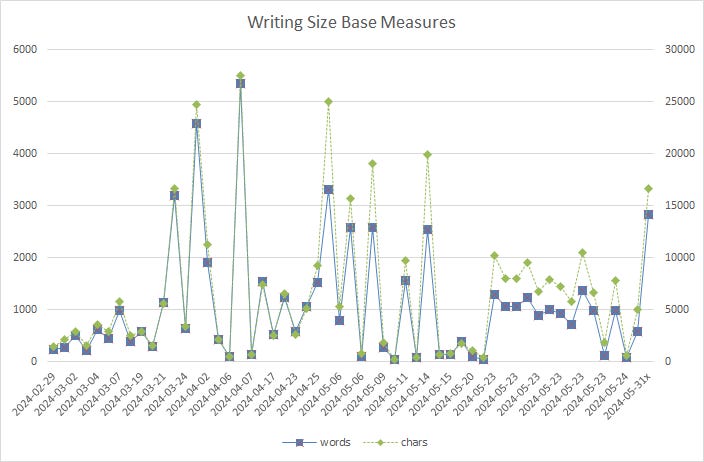
Graph Candidate 2: Another graph in my workbook has two measures of post size from the readability metrics: words and characters. It shows that the two track closely. (This is unsurprising, since the characters-per-word averages above are fairly consistent!)
Like most of my other mockups in Excel, it already used differently-scaled Y axes. One parameter’s range is 5x the other, so a single scale won’t work well for both. That makes it not a good choice for a single overlaid Datawrapper graph.
It might work with multiple graphs stacked vertically - a “‘Multiple Line” chart, which Datawrapper recommends. I don’t think the small gaps (such as on the ten May 23 articles) would be as obvious, though.
Graph Candidate 3: One of my draft readability analysis graphs shows three parameters: reading Grade Level (years of education needed), Sentences per Paragraph, and Words per Sentence. This looks like a useful experiment choice.
Comparing Excel and Datawrapper
Three chart implementation options (A, B, C) of this graph are shown below, for comparison.
Option A: Here’s an Excel chart draft, rescaled so both Y-axes have the same units.

Option B: I recreated the chart in Datawrapper by importing the data. I was able to do most of what I wanted with the viz, except:
No vertical Y-axis label.
No control over position of the legend (only at top or suppressed).
No practical way to fit even half of the X-axis labels (dates). Datawrapper shows only a subset they select (limit on the max number of X tick marks).
My posts aren’t linear over time (there was a burst on May 23, which is why that date appears twice in the tick marks). This could be a bit confusing, although the specific dates aren’t super important here.
On the plus side, Datawrapper offers an annotation box under the title, provides author credit and a link to the data source, and allows tailoring the parameter titles in the legend. And it supports exploring the data. Here is the interactive Datawrapper equivalent, overlay style:
Option C: As an alternative to the Line chart overlay, Datawrapper supports a “Multiple Line” chart which can vertically stack related graphs. This allows interacting with the data on one graph & seeing related values on all graphs.
When I changed the chart type to Multiple Line, the editing took about 12 minutes. The time was part learning curve (it’ll be faster later), and part investigating a few more quirks:
The annotation was duplicated on all 3 sets of axes. This was easy to fix.
The markers disappeared. There’s no apparent way to use markers on data points when there’s only one line per set of axes.
I can’t mouse over that “40” for WPS and have it show me the values for that date on all 3 charts. (If it works for you on your machine, please let me know!)
Here’s how Option C turned out:
Before I publish my May retro, I’ll try changing the upper limit of the scale to 50 and see if that works better for mouseovers. I’ll also try increasing the vertical height of each chart to see if that enhances mouse selection on the lines.
POLL 1: What do YOU think of these 3 options for Experiment 2?
That’s enough on Datawrapper graphs for now! Let’s move on to a new type of visualization: data tables. (If you’re not interested in data tables, feel free to jump ahead to the Conclusions.)
Experiment 3: A data table
On May 23, I published an article in 6 'P's in AI Pods with a 9-row, 8-column table (“9 ethical genAI music tools [Unfair Use? series, PART 3]”. The table summarized my findings about the 9 genAI music companies certified as Fairly Trained. Now, 9 rows and 8 columns is not a huge table, but it was big enough to overflow vertically and horizontally on my laptop screen at normal resolution.
Option A: I generated a big (2268 x 3605 pixels) screen shot image of the table from Excel, and published that in the article:

Option B: I created a Datawrapper equivalent from the Excel file. This took about 15 minutes. One key decision was required: ‘visualization only’ link or ‘for sharing’ link type. Based on the advice on the documentation about resizing of ‘visualization only’, I decided to use the Datawrapper visualization ‘for sharing’ link type. (In Substack draft edit mode, it looks identical to the ‘visualization only’.)
With both link types, in draft edit mode, the table looks truncated on the right in the middle of the 7th column. However, a horizontal scroll bar at the bottom allows viewing all 8 columns. (I didn’t realize this at first. The scroll bar only shows up when you happen to go there and mouse over it. This is one of my pet peeves in browser UX: I always want the option to make scroll bars stay visible. 😏
Datawrapper let me configure the viz to pin the first column, so the company name is still viewable when scrolling the table to see the rightmost columns.
A few minor gaps were apparent in the data handling and visualization:
Datawrapper does not allow configuring a vertical grid line on far right side of the last column. (To balance the look, I removed the vertical grid line on the far left side.)
Line breaks within a data cell are collapsed. “Endel 2018” got wrapped onto a single line. (It might be possible to handle this by embedding HTML, e.g. <br>, in the data cell. I’d rather not do that.)
Data files with merged cells may not be fully compatible. The vertically merged cells for Tuney were un-merged. Datawrapper does have a workaround for merging overflowing cells with blank cells to their right, which was useful in this table. However, that workaround doesn’t address vertical merging. (Tonight I found a recommendation in the help to avoid merged cells, i.e. get rid of them when preprocessing the data before pointing Datawrapper to it.10)
On the plus side, the Datawrapper embed is searchable, sortable, and should adapt automatically to dark mode and other UI preferences for readers. Here’s the interactive embedding from Datawrapper (option B):
Option C: Datawrapper offers the option to generate a static PNG image of the table visualization. At the default 900 pixel width, the last column was truncated on the right. After I increased the PNG width setting to 980 pixels, it was fine:

Aside from the 3 gaps noted above under option B, the Datawrapper table image (option C) is nearly identical to the original Excel image (Option A).
POLL 2: What do YOU think about these 3 options for the data table in Experiment 3?
Conclusions
From these initial experiments, using the free Datawrapper account with Substack looks like a clear win wherever its supported visualizations are a fit, for 4 reasons:
It probably took me less time to create, publish, and embed the original viz than the manual process of generating the screen shot PNGs from Excel, inserting the images, and adding the alt-text.
I can improve and republish a visualization at any time without needing to edit and republish my Substack post.
Updating a draft post after making changes to the data visualization is faster with Datawrapper than with the manual Excel process. All I have to do is ‘republish’ and the embed just updates. No rework to delete and re-attach the updated image and re-enter the caption and alt-text!
The Datawrapper visualizations give readers some nice interactivity and UX features that static PNGs just don’t have.
I was surprised and disappointed that the ‘combo chart’ style and multiple Y axes I need for Pareto diagrams aren’t supported. I can probably avoid the data-related problems with table visualizations by carefully setting up my workbooks in future.
What’s Next?
For these experiments, I just pasted or uploaded static data. I need to look a bit more into how to set up Datawrapper with access to cloud-stored data files. It would be nice to automatically get updated vizzes that reflect my latest data.
Cloud storage won’t necessarily save me from having to point a duplicated viz to a new file. I don’t see a way to constrain which rows are included in a given viz. Viewing an old article months later would show different data than when it was published - not what readers or I would want.
I also want to look into alternative ‘shoestring’ tools that can support the combo chart style. Two potential candidates are Tableau Public (free plan)11 and Google Charts12 (also free).
My next step is going to be using Datawrapper on the graphs in my end-of-May retrospective (other than my Pareto-style charts). I’ll report back on how well these promising results hold up 😊. I’d love to hear:
what you all think about these experiments, or
about your own experiences with embedding Datawrapper or another visualization tool into Substack posts!
Credits and References
Thank you to for sharing her insights on these dataviz tools, and to Heiner Romero Leiva for his feedback on the draft article 🙂
Credit to the classic 1939 movie “The Wizard of Oz” for Dorothy’s line “Lions and tigers and bears. Oh my!” which inspired the title of this post.
Tableau Public: https://public.tableau.com/app/about
I've been using Datawrapper regularly for several months now. One lesson I've learned (with the maps, at least): Even though Substack sort of picks up a post image from the Datawrapper embed, it's better to export a datawrapper map as a PNG image, and then put it in the post Settings as the social media image. This is especially true if the data in the embed is changed; the post image seems not to update.
TIP: Before exporting the PNG, with the maximum map height set to the default of 600px, set the border to about 40px. This puts enough white space around the outside of the image that it will still fit within Substack's 420x300 aspect ratio post image without truncating my titles or footers.