



Grammarly vs. Readability Formulas: initial data and findings
First-month impressions of Readability Formulas and how its data compares to Grammarly's free plan. I'm using them to improve my writing on a shoestring budget.

This post summarizes what I learned in June 2024 1 from using my two new tools to help me improve the readability of my writing on an “ethical shoestring” budget. If you’re curious about better writing, too, read on!
Post contents:
Experiment 1: Rich Text vs. Plain Text Input
Experiment 2: Impact of URLs in Post Texts
Experiment 3: Discrepancies in June Cases
Acronyms
FKGL = Flesch-Kincaid Grade Level
FRE = Flesch Reading Ease
GR = Grammarly
RF = Readability Formulas
If you’re a new reader or subscriber, welcome!! Here’s the context for this post 2:

Experiment 1: Rich Text vs. Plain Text Input
I ran both tools on a draft of the “Write On!” post, with rich text input and then with plain text input.
Grammarly (GR) results show tiny differences between the two input formats.
Readability Formulas (RF) results are identical for both input formats.
The counts and metrics common to both tools are close, but don’t match.
GR does not show a line count. However, based on these numbers, GR may be automatically using the line count in formulas instead of the sentence count, as RF does (and says it does).
The character count GR shows appears to include spaces. However, their math for Average Word Length (Chars per Word) only works if they are using the character count without spaces (which they do not show).
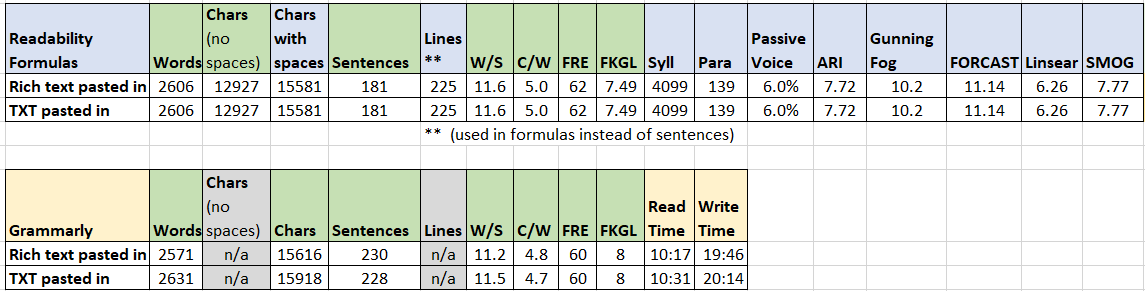
Rich text is fine: Since the differences in metrics between input formats are so small for GR, and there are no differences for RF, I plan to skip the TXT step and paste rich text directly into the tools for scoring.
Experiment 2: Impact of URLs in Post Texts
I also ran a test on a draft short LinkedIn post text. The draft had a long Substack URL (before LinkedIn shortened it). This test confirmed that URLs also impact GR. With the URL, GR gave a Flesch score of -19 - yes, negative! When I removed the URL, GR re-scored the post as 59. Comparing the “Word count” statistics indicates that the tool counted the URL as 1 extremely long word and 1 sentence. I’m sharing this information with GR support. RF was similarly affected by the URL, with scores of 11 and 63.
This Datawrapper table shows details on how GR and RF did on this example:
Experiment 3: Use of RF and GR on June Cases
Discrepancies
For my June retrospective, I used both tools on my entire set of 20 June postings, plus 9 posts from March-May. I found some quirks.
RF doesn’t handle sentences ending with “… AI. …” properly 😦. In two cases in the same short June 20 post, its processing removed the “I.”, conflating two sentences into one. I noticed it because GR counted 7 sentences (correctly, based on my manual count) and RF counted 5. That’s a 40% difference which jumped out at me. It would have been harder to spot on a longer post. The FKGL values also differed (by 2.41 grades), an outlier which also caught my attention.
As a test, I modified the text to say “AA” instead of “AI” in both places. The new metrics aligned nicely between RF and GR. The count of cardinal numbers dropped from 3 to 1. Perhaps RF was identifying “I.” as a roman numeral, despite the “A” in front of it, and discarding it? Odd bug!
Like Word, GR uses a different character count in its ratio calculations than it displays in the report. Calculated values for characters per word are significantly higher than the values displayed in the reports. (Example: for 14 posts for June, calculated average= 5.9 and min=5.6, vs. displayed average=4.6 and max=4.9). The difference appears to be mostly due to excluding spaces. This makes total sense, but the count of characters without spaces isn’t included in the GR reports.
What The Data Says
GR’s only grade level metric is FKGL (Flesch-Kincaid Grade Level). RF offers:
FKGL plus 8+ other grade level metrics for readability, and
a composite measure that combines 7 of them (including FKGL).
This graph shows the RF composite and the 7 metrics it includes. 29 posts is only a subset of my 2024 writing, but this data shows pretty clearly that different metrics have clear tendencies to score higher or lower on the kinds of technical articles I write.

I compared GR’s FKGL to RF’s FKGL and to RF’s composite. On average, GR FKGL is within 0.4 grade level of RF’s composite, and within -0.8 of RF’s FKGL. GR only reports grade level to the nearest whole number, so a 0.4 difference isn’t meaningful. This means GR and RF are close enough that I can save effort by using only RF, not both.
Conclusions
Here are the questions I wanted to answer with the data from my first month. (And the answers 😊)
Q1. How do Readability Formulas measurements compare to Grammarly? Can I trust using just RF?
A1: Yes! RF and GR are pretty close in their grade level results (FKGL, or Flesch-Kincaid Grade Level) and within 5% for FRE (Flesch Reading Ease). Using just RF should be safe for the future.
Q2. Is FKGL the most useful grade level metric for me to use? If not, which Readability Formulas measurement looks most relevant for my writing?
A2: RF’s composite looks like the most useful guide for judging how readable my writing is, for 3 reasons.
The RF FKGL is more optimistic (predicts lower grade levels) than RF’s composite. I’d rather err on the pessimistic side.
The RF composite reflects factors FKGL doesn’t count, such as (over-)use of polysyllabic words. If I used only FKGL, I might miss noticing an issue with readability of my writing.
The RF composite aligns more closely with GR FKGL than RF FKGL does.
The RF help on choosing a formula (below) suggests Dale-Chall and Fry Graph. In spite of this, I had already ruled those two out for my technical writing. (See this link for rationale 3.)

So I’ve decided to use this composite “Average Reading Level Consensus Calc” (AvgGL in my graphs) day to day. The graph above now updates automatically when I log newly published posts. This will help me spot any anomalies.
I am also monitoring the Flesch Reading Ease scores from RF.
What’s Next?
My June retrospective has more info about how I used these tools during June, if you’re curious. My agileTeams retrospective for July (in early August) will recap how these two tools are working for me and what I’ve learned. See you there 🙂
References

Context for this post:
Write On! Choosing From 7 Free Tools For More Readable Writing On A Shoestring

Most of us have to write for our jobs and daily lives. We write emails, letters, resumes, and so much more. Some of us even want to write (hello, Substackers 👋). I’m working this year on becoming a better writer. If you’re curious about better writing, too, read on!
Why I don’t use Dale-Chall or Fry Graph for scoring readability of my posts:
What’s “readable”? 16 readability metrics and what they miss

My main post on readability (metrics, tools, and evaluations) is here (coming soon!). Four bonus pages provide details: Readability features of Microsoft Word and why I’m looking for a new tool. What “readable” means, 16 metrics, the 6 I chose to evaluate, and why. [
Hi ... I read with interest the "Average Reading Level Consensus" that is used to calculate the normed average of various readability formulas. The "Readability Formulas" website, however, doesn't really state specifically how this normed average is computed. Any idea what the ARLC formula looks like?
Hi ... I read with interest the "Average Reading Level Consensus" that is used to calculate the normed average of various readability formulas. The "Readability Formulas" website, however, doesn't really state specifically how this normed average is computed. Any idea what the ARLC formula looks like?