
A tale of two LLMs: How ChatGPT and Copilot gaslit us in completely different ways
Is there really an "Open Substack mirror"? Some annoying and odd discoveries Lakshmi and I made while analyzing data from "AI, Software, & Wetware" interviews for our ABC conference presentation.

I’ll be co-presenting on everyday ethical AI this Friday at the Association for Business Communication (ABC) conference this Friday. and I have been working together on using common AI tools (and some non-AI tools) for analyzing the data from the first 80 AI, Software, & Wetware interviews. Our goal is to summarize how real people worldwide feel about AI and ethics. We are using multiple Large Language Models (LLMs) and ran into some strange quirks last weekend, including the supposed existence of an “Open Substack mirror”.
ChatGPT Confusion
Within the space of our 1-hour Zoom call last Friday night, Lakshmi’s licensed copy of ChatGPT Pro (GPT-5):
Gave positive scores to almost every interview, even interview #059 which we chose as a negative benchmark. (It has clearly negative sentiments such as
“I would never intentionally use AI”.)Repeatedly used the data from the AISW059 PDF file when we told it to use only the AISW041 PDF file.
Claimed that about half of the PDF files we had just uploaded in the previous command were not readable. Mind you, we’re only talking about 80 files, and not very big ones — megabytes in total, not gigabytes or terabytes. And this was the Pro version in a fresh new conversation.
ChatGPT was clearly mishandling the PDF files she uploaded. We wanted to reduce the content of the files to exclude my interview questions anyway, and to limit the content to plain text only, to reduce possible sources of bias. So we decided to take the opportunity to have ChatGPT help us construct the reduced set of content we wanted to analyze.
That … didn’t work well. Lakshmi tried giving ChatGPT the URL for interview 032, an engineering program manager in Costa Rica, so that it might retrieve the correct content. It failed.
This reported failure actually makes sense because I have the Substack setting on the newsletter set to block AI training. So yay, ChatGPT sort of respected my setting. That’s the only good news.
The kicker: ChatGPT offered to try to get the interview content from what it called an “Open Substack mirror” (‼️). Existence of such a mirror would mean ChatGPT or one of their partners wasn’t really respecting our opt-out settings after all.
Curious to see what that mirror was and if it would work, we agreed to let it try.
Sure enough, ChatGPT came back with the text of an interview that it claimed was a successful retrieval of interview 032. What it came back with, though, was not interview 032. The content was for an anonymous embedded software developer in Costa Rica who supposedly graduated in 2014.
Not only was the interview not the one we requested, I never interviewed any embedded developer from Costa Rica who graduated in 2014. ChatGPT and its supposed Open Substack mirror got the country right, but otherwise the returned interview was made up — and useless to us. 🙄
I’m still mulling that supposed ‘Open Substack mirror’. As a mirror, it’s more like a funhouse mirror than a real one! For people who’ve opted out of AI training through our Substack settings, is it sort of good news that trying to retrieve the interview through the mirror didn’t work, even though ChatGPT claimed it did?
Lakshmi and I resorted to manually rebuilding 80 smaller answers-only files in DOCX format, removing photos, titles, and my interview questions and comments. It was tedious, but the most efficient way to get to our real work and know that we could trust that the content would be accurate.
Dancing in the dark with Copilot
Earlier last week, while Lakshmi was running OpenAI ChatGPT Pro on our data, I ran Google Notebook LM. ChatGPT’s numbers were all over the place, and I got much lower numbers with Notebook LM. Many of the lower numbers aligned better with my intuition about the guest’s sentiment. Giving both LLMs a prompt with a specific scoring range (-1 to 1) helped, but ChatGPT and Notebook LM were still quite different. I hadn’t expected that.
So for fun, I tried Mistral Le Chat with the same files and prompt. It was strongly positive, much more so than ChatGPT!
Then I tried Microsoft Copilot. Copilot was mostly positive, but not as much as Mistral.
For all of these, I initially used the same PDF files as Lakshmi did with ChatGPT, and the same simple prompt for scoring AI sentiment in the range -1 to 1.
After reducing the files to only the guests’ answers, as described above, we re-ran all four LLMs. In order to run Notebook LM, I converted the DOCX files to TXT format. (Why? Because Notebook LM pretends it doesn’t know how to read DOCX, although it obviously could do so easily. 🙄 And converting DOCX to PDF would have been more work and made bigger files for the LLMs to digest.)
Using the TXT files as input for all of the LLMs not only removed some potential biases, it made the files much smaller (a few MB total) and removed an internal LLM processing step to convert from PDF or DOCX. We hoped the LLMs would be less likely to hit token or context limits.
I ran a few sample TXT files in each LLM that night, then hibernated my laptop with the LLM browser windows left open. I picked up the work the next day and re-ran all four models with all 80 files.
I expected similar scores from Copilot on the TXT files compared to when I re-ran the scoring with the same simple prompt the day before. Uh, no. Copilot now was even more positive than Mistral, even on the negative benchmark interview. Every one of the first 20 interviews was scored as positive! Not only was it different from what Copilot gave me the day before, I knew that it wasn’t right.
Meanwhile, NotebookLM and even the highly-optimistic Mistral rated the same benchmark negative interview #059 at -0.8 and -0.9, which made sense. And compared to when I ran the same interviews with the same scoring prompt a day earlier, their scores were fairly repeatable.
I asked Copilot to explain its scoring. Among other things, it said that it was counting awareness of ethical concerns as a positive. Aha! I wanted expressions of ethical concerns to be handled as a more negative sentiment.
From my experiences with these interviews, guests who commented about reservations on the five concerns in my Everyday Ethical AI book (environmental impact of data centers, unethical data sourcing, exploitation of workers, model biases, impact on lives and livelihoods) did so because they found those concerns to be a downside of using AI, or a factor that kept them from using AI more. So those comments should reduce the score on AI sentiment.
I had not told Copilot to score ethical concerns about AI as positive sentiment. Plus, Copilot didn’t seem to score sentiment that way just the day before. With the same interview files and the same prompt, I got very different answers on two different days, using the same conversation instance.
I updated my prompt to clarify that concerns about ethics should reduce the score, and ran it again. I checked some of the individual interviews, including #059. Copilot still scored it as fairly positive.
When I pointed this out to Copilot, it acknowledged that its score was inconsistent with the many strong negative comments in #059. Copilot apologized and said it would adjust the score to a less positive number by modifying internal weights. But the first results with those supposed adjustments didn’t change at all. 🙄
We did this dance a few times, with me trying various prompts on ways to weigh ethical concerns and practical uses, and checking some benchmark interviews. I added, then ended up removing, a prompt telling Copilot that practical use of AI should raise the score; it appeared that this caused Copilot to over-weight wording it was already treating as positive.
Inspired by the Lehigh study that telling a LLM to ignore biasing factors could help to reduce the bias in its financial recommendations, I also added a sentence to the prompt telling Copilot to ignore demographics like race, age, gender, etc.
At the end of the day (well, night), the Copilot scores were still overall positive, but the score on #059 finally got below -0.5, to -0.8 (on the scale of -1 to 1). This was at least comparable to the other LLMs, which now scored #059 at -1, -0.9, and -0.9 with that revised prompt. The more positive (IMHO) interviews still had positive scores.
To ensure consistency, Lakshmi and I then re-ran all of the other LLMs with the updated prompt and the TXT files.
I ended up trying a fifth LLM - Anthropic Claude. Claude showed a somewhat similar pattern to Mistral and Copilot. But none of that proved that any of them were right. (They might have used common, WEIRD1 unbalanced training datasets, or other factors that made them give somewhat similar results.)
Here are the preliminary distributions of AI sentiment scores for the five LLMs:
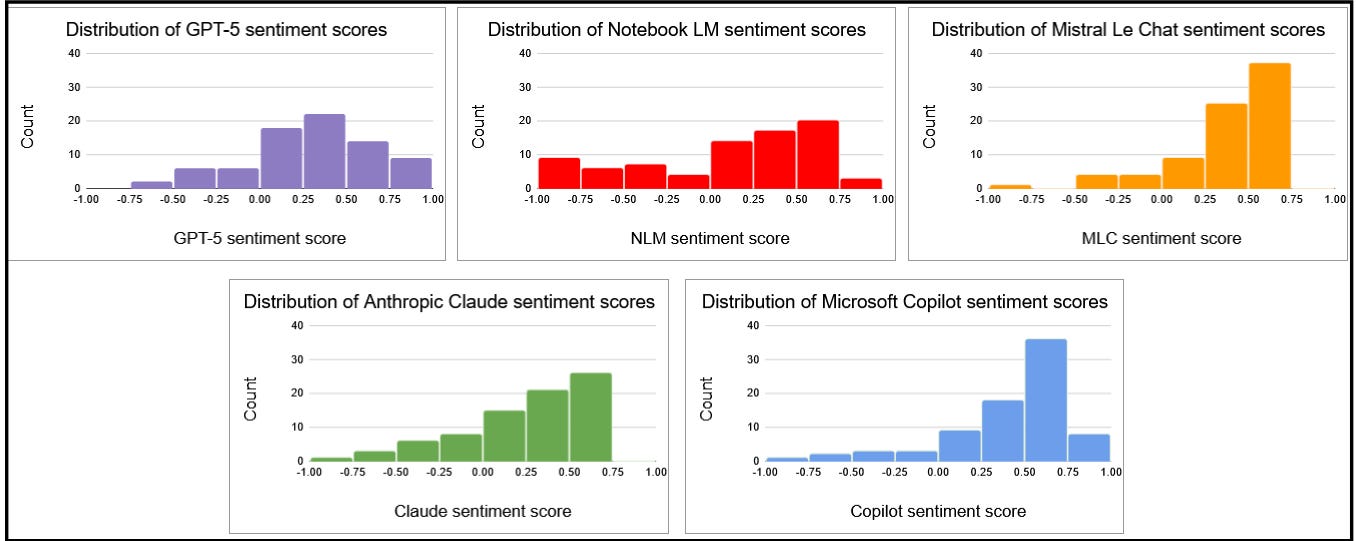
ChatGPT looks suspiciously like a normal distribution (bell curve). There’s no reason to believe that the opinions in the underlying set of interviews are normally distributed, although it’s possible. And I’m really wondering whether most of these LLMs might be trained to respond with positive spins on sentiments about AI in particular, as a matter of company self-interest.
Have any of you ever seen this kind of variability in sentiment scoring when comparing multiple LLMs with the same prompt and same set of files?
At this point, I don’t feel confident about trusting any one of them with scoring these AISW interviews. We’re using an aggregate of all five LLMs (averages) for reporting our findings at the conference. I also tested a scoring approach used by judging panels in some Olympic sports (drop the high and low, then take the average); it didn’t make a noticeable difference.
Next Steps
We’re finalizing the data analysis for the conference this week. In particular, we’re looking at common themes and patterns in sentiment about AI across gender, race, ethnicity, age, type of business, type of job, geographic location, and even whether guests use Substack, LinkedIn, or both.
We’re definitely not stopping this analysis on Friday. I’m intrigued by the discrepancies among these LLMs, and we will be investigating further.
Trying other LLMs is one option. Unfortunately, so far, the ethically-developed chat.PublicAI.co is refusing to validate my email address to let me use it. 😔 I’ll pick that up next week, and I will definitely use it as soon as I can get in. I may try Perplexity too; we’ll see.
In addition, one of the professors we’re collaborating with for the ABC conference is doing good old-fashioned Textual Analysis with ‘close reading’ of the interviews. After the conference, she will be assigning scores based on her expert human judgment and analysis of the interviews. Her scores will give us some ground truth for verifying which of the LLMs (if any) are actually accurate for guest sentiments about AI.
Curious to hear about the results of our data analysis on how people feel about AI and ethics? Stay tuned! After the conference, I’ll summarize what we’re learning here in Everyday Ethical AI, and update you all from time to time.
We’ll also share an article (or a few) in 6 ‘P’s in AI Pods (AI6P) about the more technical details of the analysis, what we find when investigating the LLM discrepancies, and what we’re working on next.
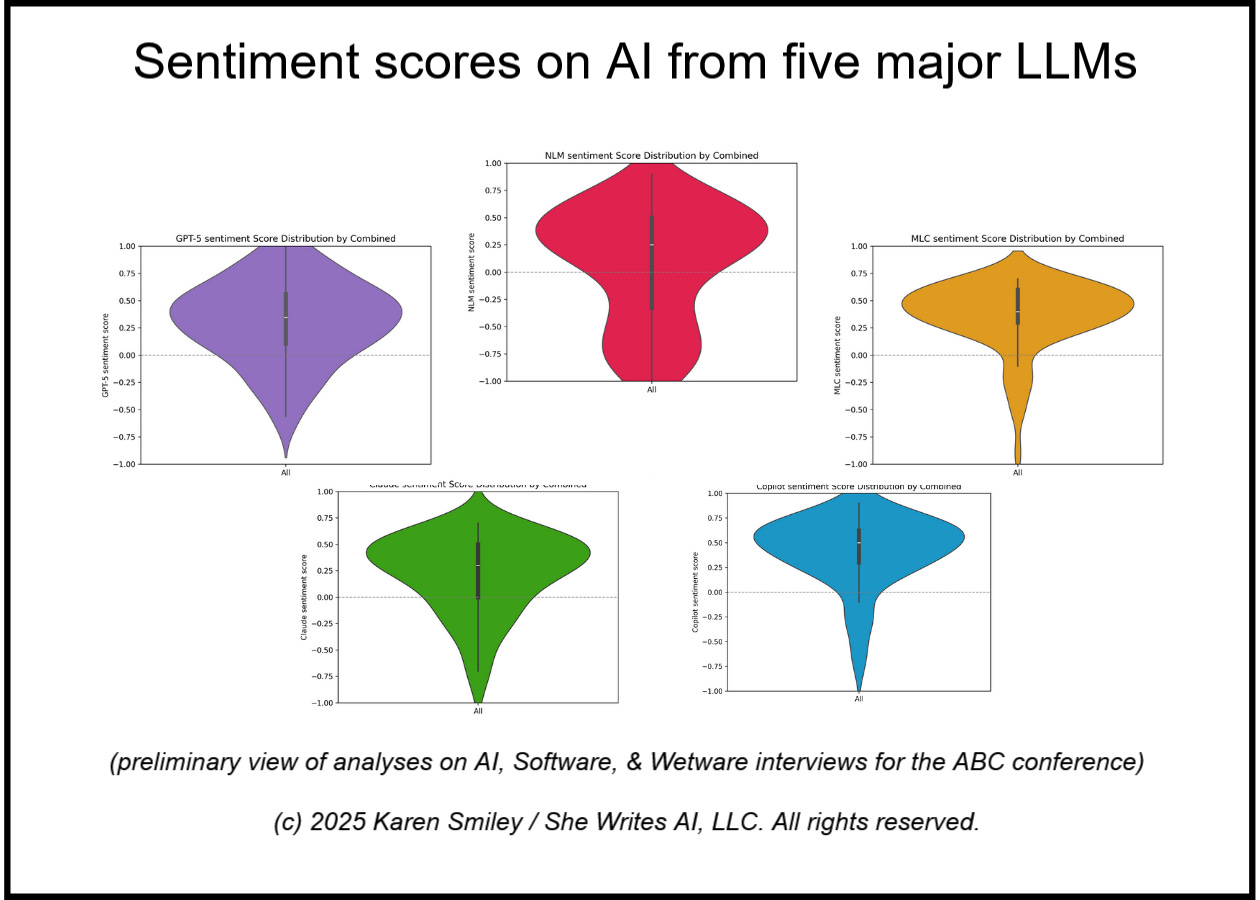
And if you’re into data visualization and love violin plots as much as I do, you definitely won’t want to miss those articles. Here’s a preview. 😊
Credit to
for bringing the WEIRD acronym to my attention in her recent post, Be WEIRD or Get Left Out of AI! (WEIRD = Western, Educated, Industrialized, Rich, Democratic - for more info, see the Open Encyclopedia of Cognitive Science at MIT)
Yes. I worked on a textbook chapter about using LLMs to handle large, open-ended survey data and it was a disaster. I thought GPT-5 and the latest models would be more capable, and I was wrong. Validity and reliability, as well as replication, are still major issues.
I would love to know what prompts you used to interact with the systems.